Components of an RL-ready model
Summary: This page contains general information about the Reinforcement Learning Experiment in AnyLogic; it’s not Alpyne-specific, but it’s a prerequisite to using it to its fullest.
The Reinforcement Learning (RL) experiment is a special type of AnyLogic experiment for allowing RL-ready AnyLogic models to be used on specific RL platforms. The experiment provides a platform-agnostic framework for declaring the necessary components in an RL training setup.
This experiment type is available in all three editions of AnyLogic; for PLE, limitations still apply in the exported model.
Unlike other experiments, the RL experiment cannot be directly executed by end-users within AnyLogic. This is because AnyLogic does not have any embedded RL algorithms. Thus, it can only be directly executed by compatible platforms (e.g., alpyne, Azure ML via the Plato Toolkit).
From your perspective (as a modeler), the purpose of this experiment type is a framework for information and thus there is no user interface - you simply fill out the fields of the experiment according to your specifications.
Filling out the RL experiment
Before using a model in Alpyne, the following needs to be decided upon and implemented:
- Configuration
This is a set of data fields which define the starting conditions of each simulation run.
It achieves similar behavior to typical AnyLogic parameters, however it is a layer on top of them. This means you can choose which parameters you’d like to expose to the exported model (similar to how Cloud inputs work).
In the “Configuration” section of the RL experiment, you define the various names and types in the table. The code field following it is where you apply the values passed from your Python environment to your model.
Any parameters not overridden in the code field will be set to their model-default values.
Warning: This code field gets called near the very beginning of the model creation process, only after the default parameter values have been set. Therefore, you should only assign values and not try to access populations or call functions (including parameter-based ones, such as
set_parameter(...)).
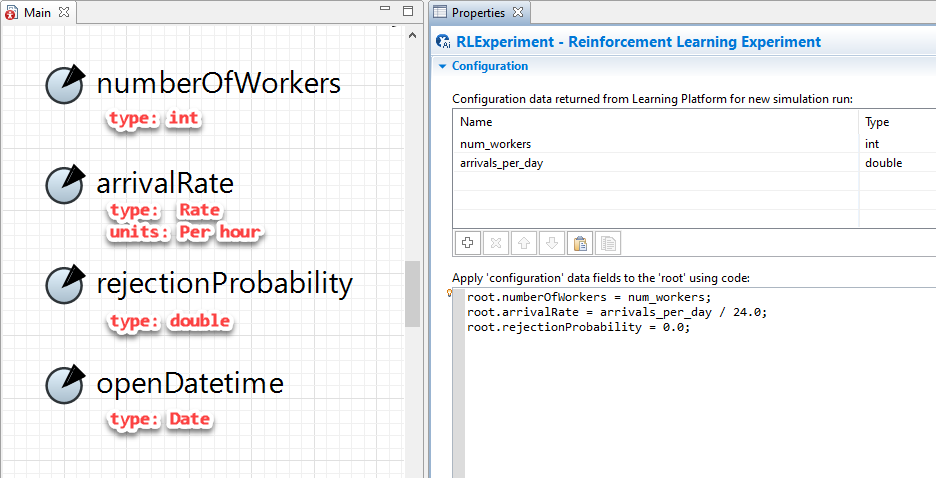
Configuration example that shows different ways of setting up parameters: numberOfWorkers and arrivalRate are exposed to the Configuration, rejectionProbability is hardcoded to be 0 on each run, and openDatetime will use its model default value.
- Observation
This is a set of data fields which define the current state of your simulation run, at the point the observation is taken.
It is defined in the “Observation” section of the RL experiment, where you set the names and types in the table. The code field is where you set the value of fields with the relevant values in the model.
- Action
This is a set of data fields which define what sort of dynamic interaction can occur.
It is defined in the “Action” section of the RL experiment. You set the names and types in the table. The values will be sent from your Python code to the model, where the code field will take the values and apply them to the simulation model.
- Terminal/Stopping conditions
This is how you wish to define when the simulation should be stopped or in a terminal state. This could be as the result of an improper sequence of actions putting the model in a failing state or simply a temporal end point.
You can set the start/stop time and date in the “Model time” section of the RL experiment. The “Observation” section also has a field that expects a boolean value. If the Java keyword “true” is passed, this will mark the simulation as done.
- Randomness
Similar to other AnyLogic experiments, you can define whether the simulation should be executed with a fixed or random engine seed.
This is defined in the “Randomness” section of the RL experiment.
Note
Both the start/stop time/date and engine seed can be overridden within Alpyne (i.e., post-exporting the model).
About the takeAction method
As the name suggests, the takeAction method should be called in your model when it’s desired for an action should be taken. In other words, it should be called at certain “decision points” that you want some action to be delegated to the RL algorithm. Generally speaking, these points can be event-based or time-based.
For an example, say you have a model of a bank and your RL algorithm will be trained to minimize queue times by selecting which queue an arriving customer should wait in. In this case, you might call takeAction in a relevant callback field corresponding to when a new customer arrives to the bank.(e.g., the On exit field of a Source block).
If instead your RL algorithm is trained to maximize employee happiness by determining every hour who should go on a break, the takeAction may be placed in a recurring Event object.
This method belongs to the class for the RL experiment and takes any agent as an argument. Provided that you are calling the method from inside an agent (most cases), you can use the Java keyword this to refer to the current agent. Thus, it can be called by having the following line:
ExperimentReinforcementLearning.takeAction(this);
Alternatively, you can replace “ExperimentReinforcementLearning” with the name of your created RL experiment.
Warning
If the takeAction method is called and the model is running in a user-environment (e.g., another experiment type), a model error will be thrown! If you only plan on running the model in an available platform, there’s no issue. However, if you want to run the model without needing to manually toggle this line of code, see the next section.
About the optional “mode” parameter
For most AnyLogic experiments, the same base model can be used without any extra, required modification. For example, you can run a Simulation or Monte Carlo experiment without needing to edit the model.
In contrast, the takeAction method - which is needed to trigger a step, as part of setting up your model for RL training - will throw a model error if it’s called while the model is in a user-based environment.
If you plan to have the model run for both RL training purposes and for “traditional” experiments, it’s impractical to require manual editing. Fortunately, there’s a simple solution: create a parameter on your top-level agent that designates the model’s desired execution mode. If this is a binary choice, this could be a boolean (e.g., “inRLTraining”). If you plan to have multiple execution modes (e.g., user controlled, heuristic controlled, RL training, RL testing), you could use an integer and the built-in Value Editor to describe what concepts the values correspond to.
After adding the parameter, you’ll need to refactor your model slightly to make use of it. For example, if your “mode” parameter is a simple boolean with the name “inRLTraining”, the code for taking an action may look like:
if (inRLTraining) ExperimentReinforcementLearning.takeAction(this);
Tip
Add a line in the Configuration section of the RL experiment to set the mode parameter to the value corresponding to calling takeAction. This way, you can be sure the method will be called, regardless of what the parameter’s default value is set to!